GraphQL
Overview
GraphQL has a well-specified query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
Ask for what you need, get exactly that
Send a GraphQL query to your API and get exactly what you need, nothing more and nothing less. GraphQL queries always return predictable results. Apps using GraphQL are fast and stable because they control the data they get, not the server.
Get many resources in a single request
GraphQL queries access not just the properties of one resource but also smoothly follow references between them. While typical REST APIs require loading from multiple URLs, GraphQL APIs get all the data your app needs in a single request. Apps using GraphQL can be quick even on slow mobile network connections.
Describe what’s possible with a type system
GraphQL APIs are organized in terms of types and fields, not endpoints. Access the full capabilities of your data from a single endpoint. GraphQL uses types to ensure Apps only ask for what’s possible and provide clear and helpful errors. Apps can use types to avoid writing manual parsing code.
Evolve your API without versions
Add new fields and types to your GraphQL API without impacting existing queries. Aging fields can be deprecated and hidden from tools. By using a single evolving version, GraphQL APIs give apps continuous access to new features and encourage cleaner, more maintainable server code.
Why
Presently we have mutliple GraphQL servers running on different infrastructure as well as mutliple third party APIs we would like to consolidate. There are mutiple goals to this project which include:
- Updating our infrastructure to be more modern, scalable and transferable.
- Updating our graphql servers so they follow a common code and implementation pattern.
- Unlocking omnichannel content and data retrieval through schema stitching and custom resolvers.
Examples
Account page / Customer profile
Currently our customer profile is fragmented between Hybris, Mobile, Exponea and NewStore. To deliver a more feature rich Account page we should stitch data from all above systems. To do this effectively we would develop a custom resolver that could do this in a single call. Once we have achieved this some functionality we could unlock would include:
- Online and in-store orders can be viewed in a single view
- Check the status of order fulfillment. This generally means buy from anywhere and fulfill the order from anywhere. An example of this is picking up part of your order in-store or even shipping from store when a DC has no stock.
- Improving our returns process as we can process in-store orders online
- Duplicate some views and functionality from mobile such as:
- RCC Member Card
- Calendar (Rides/Events/Escapes/Virtual/Challenges)
- Chat (Syned across platforms)
Products on mobile and web
Currently we only surface products on the web. We have a few challenges around showing products that are in stock so we use techniques such as reserved stock to make sure we can fulfill orders. With the introduction of NewStore, as well as moving product enrichment data from Hybris to Contentful we should be able to build a more feature rich product card with accurate and up to date price and stock levels as well as giving the option to geolocate and show stock levels in your closest store.
How
We will achieve the above by implementing our gateway using Schema Stitching rather than Federation
Why Stitching
More information on why we chose stitching can be found here
One of the main benefits of GraphQL is that we can query for all data in a single request to one schema. As that schema grows though, it may become preferable to break it up into separate modules or microservices that can be developed independently. This is certainly how things are working currently as the mobile rides schema was developed independently of the ecommerce schema. We also have the need to stitch third-party schemas, in our case, contentful. But we should allow this to be flexible for other APIs such as Newstore.
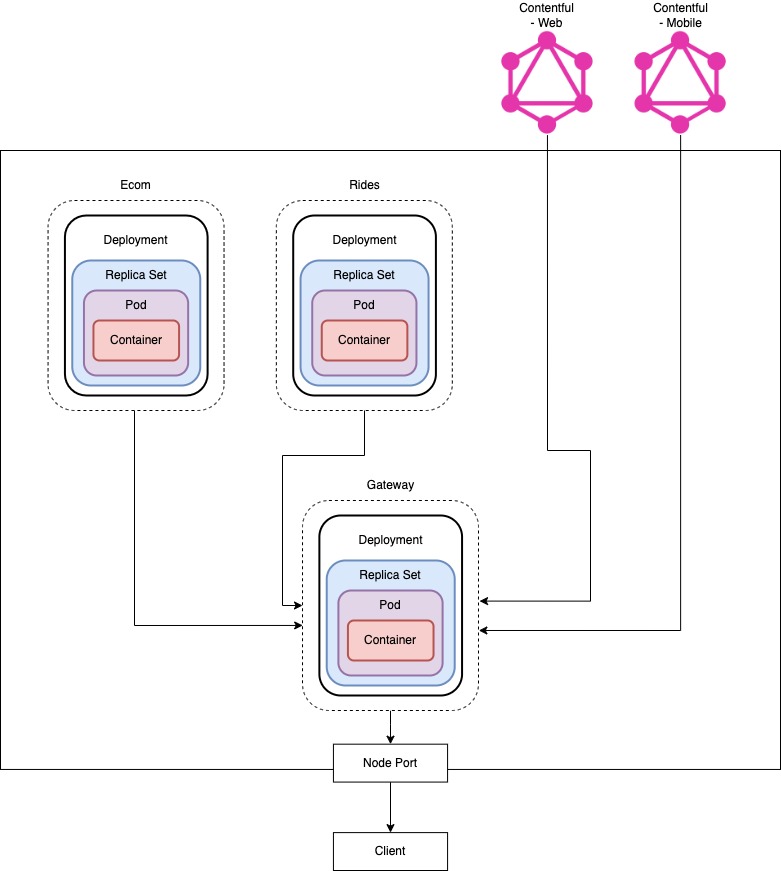
Below is a very high level architectural plan of how our Ecommerce GraphQL server and Rides (mobile) GraphQL server will interact with our Gateway (Proxy) GraphQL server. It also demonstates how we will use multiple contentful spaces when combining calls in the gateway.
FAQ
Does GraphQL replace REST?
No, not necessarily. They both handle APIs and can serve similar purposes from a business perspective. GraphQL is often considered an alternative to REST, but it’s not a definitive replacement.
GraphQL and REST can actually co-exist in your stack. For example, you can abstract REST APIs behind a GraphQL server. This can be done by masking your REST endpoint into a GraphQL endpoint using root resolvers.
Is GraphQL a database language like SQL?
No, but this is a common misconception.
GraphQL is a specification typically used for remote client-server communications. Unlike SQL, GraphQL is agnostic to the data source(s) used to retrieve data and persist changes. Accessing and manipulating data is performed with arbitrary functions called resolvers. GraphQL coordinates and aggregates the data from these resolver functions, then returns the result to the client. Generally, these resolver functions should delegate to a business logic layer responsible for communicating with the various underlying data sources. These data sources could be remote APIs, databases, local cache, and nearly anything else your programming language can access.
Does GraphQL use HTTP?
Yes, GraphQL is typically served over HTTP. This is largely due to how pervasive the HTTP protocol is.
While HTTP is the most common choice for client-server protocol, it’s not the only one. GraphQL is agnostic to the transport layer. So, for example, you could use WebSockets for GraphQL subscriptions instead of HTTP to consume realtime data.
What is a GraphQL client and why would I use one?
GraphQL clients can help you handle queries, mutations, and subscriptions to a GraphQL server. They use the underlying structure of a GraphQL API to automate certain processes. This includes batching, UI updates, build-time schema validation, and more.
Is GraphQL scalable?
Yes, GraphQL is designed to be scalable and is used by many companies in production under a very high load.
GraphQL comes with some built-in performance boosts that can help. But once you push it to production, you're responsible for scaling it across instances and monitoring performance.
What are the security concerns with GraphQL?
Most of the security concerns associated with GraphQL are typical for any API or service. A few examples: SQL injections, Denial of Service (DoS) attacks, or someone abusing flawed authentication. But there are also some attacks specific to GraphQL. For instance, batching attacks. These attacks can happen as a result of GraphQL allowing you to batch multiple queries (or requests for multiple object instances) in a single network call.
No matter the concern, it’s important to be proactive. There are many ways to securing your GraphQL server. Using a timeout, setting a maximum depth for queries, and throttling queries based on the server time it needs to complete are all potential approaches.
How does versioning work in GraphQL?
There’s nothing that will prevent a GraphQL service from being versioned like any other REST API. That said, GraphQL avoids versioning by design.
Instead, GraphQL provides the tools to continually build and evolve your schema. For example, GraphQL only returns the data that’s explicitly requested. This means that you can add new features (and all the associated types and fields) without creating a breaking change or bloating results for existing queries.