Current GraphQL Infrastructure
This will serve to document the following aspects of the current GraphQL infrastructure in GCP:-
- Terraform
- Kubernetes
- CI/CD
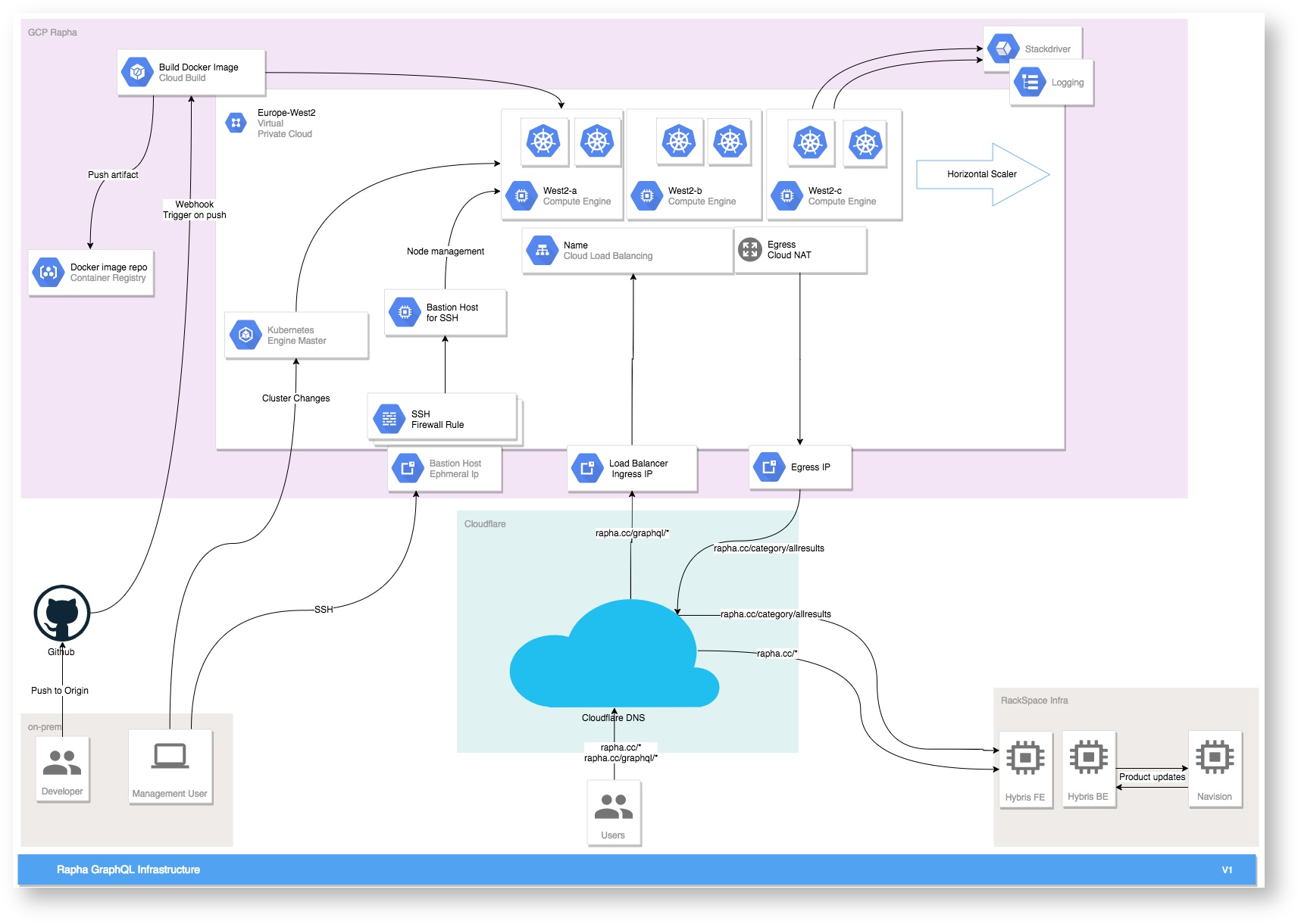
Terraform
The terraform state for this project can be found in the rapha-terraform-state bucket in the careful-alloy-221010 GCP project here.
This bucket contains the state files of the production and the various development environments.
This project is not structured using our current standards defined here, and makes heavy use of modules local to the project.
Modules
These modules are referenced in the <environment>-deploy/main.tf which define the configuration of the two environments (production and staging) used with this project.
Cluster
As it's name suggests, this module creates the Kubernetes cluster within GKE and provisions the node pool that will be associated with this cluster.
Some points to mention are:-
- The master node can be accessed from anywhere, due to the presence of a
master_authorized_networks_configwhere the allowed range is0.0.0.0/0. - The default node pool, which is created on creation of the cluster, is removed once the cluster is created.
- A static external IP is created for each cluster.
Outputs
externalip- The static external IP associated with this cluster.loadbalancerip- The static external IP associated with this cluster. Same value asexternalipclient_certificate- The Base64 encoded public certificate used by clients to authenticate to the cluster endpoint.client_key- The Base64 encoded private key used by clients to authenticate to the cluster endpoint.cluster_ca_certificate- The Base64 encoded public certificate that is the root of trust for the cluster.host- The IP address of this cluster's Kubernetes master.name- The name of the cluster.custom_pool- The name of the custom pool associated with the cluster.
Bastion
This module creates a bastion node which can be used to access the cluster for management purposes. The bastion created is locked down so SSH access is only possible from defined ranges - the range used is 167.98.53.108/32 which is the IW Exponential E CIDR range.
The bastion node created is relatively small, f1-micro, with minimal configuration indicating that this is simply a jump node however as the SSH keys that are used to access this remain unknown this module again is somewhat redundant.
Cloud Builder
This module creates the Cloud Build trigger which listens for pushes on certain branches to the cloud repository hosting the GraphQL code in GCP.
⚠️ This is no longer required.
Cloud NAT
This module creates the core networking infrastructure used by the GraphQL kubernetes cluster.
The networking infrastructure is made up of 5 key components:-
- A VPC Network
- A subnet within the VPC
- A Google Cloud Router
- An external IP address
- A NAT
VPC
This part of the module, as it's name infers, simply creates a Virtual Private Cloud (VPC) network within GCP. The only additional configuration, aside from the mandatroy name, that is set is that we set auto_create_subnetworks to false so the VPC doesn't come with preprovisioned subnets and we can instead configure our own.
Subnet
This part of the module creates a subnet that is to be associated with the aforementioned VPC. This subnet will contain all of the pods & services in the kubernetes cluster, and so two secondary IP ranges are also configured as part of this subnet to allow for easier management and identification based on IP addresses - there is 1 secondary range for services and 1 for pods.
As well as this, the private_ip_google_access argument is set to true which allows machines within this subnet to access Google API's and services without the need for an external IP address.
Cloud Router
This part of the module creates a Google Cloud Router, which is the precursor to a NAT service. The configuration for this is relatively run of the mill, with the network this is attached to being the VPC created previously.
External IP Address
This part of the module creates an External IP address that can be used in conjunction with the NAT service and Cloud Router to allow pods and services within the cluster exterrnal network access.
NAT
This part of the module creates a NAT service attahced to the Cloud Router created previously. It NAT's traffic from the subnet created earlier to create outbound connections to the wider internet by utilising the External IP Address created previously. The configuration of this is relatively standard so won't be covered in detail here.
Cloudflare
The cloudflare module simply creates a single DNS A Record for the GraphQL implementation.
For staging that record is graphql.raphadev.cc and for production it is graphql.rapha.cc, with each of these pointing to the External/Static IP Address of the CLuster (NOT the external IP created by the Cloud NAT module - confusing right).
cloud-builder-pubsub
This directory creates a nodejs10 Cloud Function which will send a slack notification, via a webhook, on any update to any Cloud Build job running from the graphql cloud repository.
As the repository this targets is no longer used, as the migration to gitlab required us to change the cloud repository too, this mechanism is redundant. As well as this, the notifications are sent to the raphadev slack account which is no longer used.
cloudflare-host-header
This directory creates the cloudflare page rules that are used to forward traffic from Cloudflare on the *.rapha.cc/graphql/ and *.raphadev.cc/graphql/ routes to the respective endpoints in GCP.
These page rules set the host header override and resolve override values to the following:-
ci.raphadev.cc/graphql/*=>graphql.raphadev.ccalpha.rapha.cc/graphql/*=>graphql.raphadev.ccuat.rapha.cc/graphql/*=>graphql.rapha.ccwww.rapha.cc/graphql/*=>graphql.rapha.cc
google-stackdriver-monitoring
This directory creates the stackdriver monitors for both staging and prod. These are both uptime checks which hit the /.well-known/apollo/server-health endpoints on the GraphQL nodes every 60 seconds. There is a maximum timeout value of 10 seconds for each of these checks.
staging-deploy
The contents of this directory are used to define the terraform configuration specific to the staging environment. As mentioned it makes heavy use of the modules defined in the modules/ directory as well as numerous variables defined in the variables.tf file within this directory.
production-deploy
The contents of this directory are used to define the terraform configuration specific to the production environment. As mentioned it makes heavy use of the modules defined in the modules/ directory as well as numerous variables defined in the variables.tf file within this directory.
The main.tf and variables.tf files are pretty much identical to those in the staging-deploy directory. There are a few small differences between the two directories isolated to the variables.tf file, which are primarily focused on the different project and environment names (e.g. graphql-staging and graphql-production for the environment variable). The notable exceptions being the cloud builder config, which for production is set to build from master branch and for staging is set to build from develop branch.
Kubernetes
staging
Deployments
This stores the 3 deployment YAML files that are used in the staging cluster.
There is minimal difference between the 3 deployments so we will use the alpha-deployment.yaml to explain the config.
Metadata
metadata:
name: graphql-alpha
labels:
name: graphql-alpha
namespace: graphql-staging
In this section we see the deployment being associated with the graphql-staging namespace, and given a name and a corresponding label. These ensure that the pods within this deployment are logically associated to one another and are appropriately namespaced.
Spec
Replicas
replicas: 1
Here we see that for this deployment, and for all deployments in this environment, we only require a single pod to be available at any time.
Strategy
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
This defines the strategy used by this deployment to replace old Pods with new ones (e.g. if a new version of the container is rolled out).
The strategy used is the default RollingUpdate value, which means that whilst the new Pods are coming online the old Pods will be retained and will only be replaced by the new Pods when they pass their healthcheck. The maxSurge and maxUnavailable fields constrain the rate at which this replacement takes place by ensuring only a single node is ever unavailable and the deployment size only ever increases by 1 to accomodate for the updates (i.e. when an update is rolled out the old Pods will only be replaced one at a time by the new Pods).
Containers
containers:
- name: graphql-alpha
image: eu.gcr.io/careful-alloy-189615/github_rapharacing_rapha-graphql:develop
imagePullPolicy: Always
env:
- name: NODE_ENV
value: 'development'
- name: HOST_URL
value: 'https://alpha.rapha.cc'
- name: ENGINE_API_KEY
valueFrom:
secretKeyRef:
name: apollo-api-key
key: APOLLO_KEY
This section defines the container image that will be deployed onto the pods in this deployment, as well as any environment variable values to embed onto this pod (these can be hard coded or pulled in from secrets).
The image itself is hosted in Googles Container Registry, and the presence of the imagePullPolicy: Always means that whenever a new pod is created the container image that will be ran on it will be pulled directly from this registry instead of using cached versions.
LivenessProbe
livenessProbe:
httpGet:
path: /.well-known/apollo/server-health
port: 4000
timeoutSeconds: 5
initialDelaySeconds: 120
This defines the check that will be used to determine if a pod is alive or not. In this case, this takes the form of a HTTP GET request to the /.well-known/apollo/server-health path on port 4000 of a given pod and checks the value it returns (or not) to determine if the node is alive or not. In essence this checks to see if this path returns a HTTP 200 or not.
There is a delay of 2 minutes (120 seconds) to accomodate for the pod starting up. The timeoutSeconds puts a bound on how long the probe has to return a value before defining the pod as dead, with the limit being 5 seconds here.
It should be noted that the path this liveness probe points to in this situation is a dumb path that always returns a 200 regardless if the code running on the pode has encountered issues or not - this should be rectified in any future developments.
ReadinessProbe
readinessProbe:
httpGet:
path: /.well-known/apollo/server-health
port: 4000
timeoutSeconds: 5
initialDelaySeconds: 120
This defines the check that will determine if the pod is ready to serve traffic. As can be seen this config is identical to that of the livenessProbe, which is not industry standard and should be changed going forward.
Resources
resources:
requests:
memory: "100M"
cpu: "100m"
limits:
memory: "300M"
cpu: "300m"
This defines the minimum and maximum resource requirements for the pods in the deployment. The values in requests define the lower bound and limits sets the upper bound, if a pod exceeds the upper limit the kernel will terminate a process with an OOM error.
The UAT implementation has slightly higher requests and limits values as deined below:-
resources:
requests:
memory: "200M"
cpu: "200m"
limits:
memory: "500M"
cpu: "400m"
Ports
ports:
- containerPort: 4000
This defines the port on which the pod, in this case the container running on the pod, should be accessed through. The port in this case is 4000 as that is the port on which GraphQL is exposed on as per here.
Services
As with the Deployments section, this folder hosts 3 variatons of the same file with one for each of the services deployed to this cluster (CI, Alpha and UAT). There is minimal difference between them so we will use the alpha-svc.yaml to explain the config.
Metadata
metadata:
name: graphql-alpha-svc
labels:
name: graphql-alpha-svc
namespace: graphql-staging
In this section we see the deployment being associated with the graphql-staging namespace, and given a name and a corresponding label appropriate for the service.
Spec
Type
type: NodePort
This defines the type of service that this file will define. In this case, the service is of type NodePort which means that the service on each Node (a Node contains a number of Pods) is exposed on a static port. In essence this is a form of port forwarding, where traffic enters into the cluster on a certain port and is then directed to another port on which the given service (i.e. GraphQL) is running/exposed.
Ports
ports:
- port: 443
targetPort: 4000
This is used in conjunction with the NodePort type to define the port forwarding functionality. In this case inbound traffic on port 443 (HTTPS) is forwarded to port 4000 on the Pod, which is the port on which GraphQL is exposed. This will proxy through a port on the Node which contains the Pod, but the port is decided by the Kubernetes control plane so doesn't need to be defined here (although it can be).
SessionAffinity
sessionAffinity: ClientIP
This defines wheteher whether sessions from end users should be sticky and what field to use to determine affinity. In this case we use ClientIP so that end user sessions are served by the same Pod.
Selector
selector:
name: graphql-alpha
This defines which Pods this service should direct traffic to based upon their name. In this case this service would target Pods from the alpha-deployment.yaml as they are all have name labels of graphql-alpha - if we wished to target Pods from the uat-deployment.yaml the value of name here would instead be graphql-uat.
Ingress
There is a single Ingress for the staging environment found here.
Metadata
metadata:
name: graphql-staging-ingress
annotations:
kubernetes.io/ingress.global-static-ip-name: rapha-graphql-staging-static-ip
kubernetes.io/ingress.allow-http: "false"
namespace: graphql-staging
Once again we use the metadata section to define the labels used by this Ingress. There is a notable difference to the deployments and services in that we make use of the annotations here to give the static IP used by this ingress a label as well as to add a label to prevent the Ingress from allowing HTTP traffic.
TLS
tls:
- hosts:
- graphql-alpha.raphadev.cc
- graphql-ci.raphadev.cc
- graphql-uat.raphadev.cc
- graphql-dev.raphadev.cc
secretName: graphql-staging-cert
This defines the hostnames that will be serving traffic from this Ingress, as well as the SSL certificate (in this case a CF Origin Certificate stored in a Kube Secret) that is used to secure traffic to those hosts.
Rules
rules:
- host: graphql-dev.raphadev.cc
http:
paths:
- backend:
serviceName: graphql-alpha-svc
servicePort: 443
- host: graphql-alpha.raphadev.cc
http:
paths:
- backend:
serviceName: graphql-alpha-svc
servicePort: 443
- host: graphql-ci.raphadev.cc
http:
paths:
- backend:
serviceName: graphql-ci-svc
servicePort: 443
- host: graphql-uat.raphadev.cc
http:
paths:
- backend:
serviceName: graphql-uat-svc
servicePort: 443
Each of these defines a HTTP rule which defines what the Ingress should do when it receives traffic looking for a given host. Take for example if the Ingress received traffic from a user targetting graphql-alpha.raphadev.cc. In that case the traffic would be directed to the graphql-alpha-svc on port 443, which we know would then forward the ports onto the alpha deployment on port 4000.
Namespace
There is a single Namespace for the staging environment found here.
A namespace allows for common elements (such as service, deployments etc) to be logically grouped together within a single cluster.
The configuration in the namespace.yaml, simply creates a namespace with name graphql-staging which can be referenced by other elements down the line (deployments, services etc).
Horizontal Pod Auto Scaler
There is a HPA present in the staging environment that is used to scale the UAT deployment only - uat-hpa.yml
This isn't required in Alpha or CI do not have the requirement to be as highly available as UAT does.
Metadata
metadata:
name: graphql-uat-autoscaler
namespace: graphql-staging
In this section we see the HPA being associated with the graphql-staging namespace, and given a unique name.
Spec
ScaleTargetRef
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: graphql-uat
This defines what element this HPA is set to scale, when required. As can be seen from the kind and name keys, this HPA is set up to scale the graphql-uat deployment.
MinReplicas
minReplicas: 1
This defines the minimum number of pods (replicas) that must be retained by the HPA, which in this case is 1.
MaxReplicas
maxReplicas: 6
This defines the maximum number of pods (replicas) that the HPA can retain, which in this case is 6.
Between the minReplicas and maxReplicas we can see that the graphql-uat deployment will be made up of any at least 1 but never more than 6 pods at any one time.
Metrics
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
This defines the metric to be used to determine when a scaling event should take place. In this context, a scaling event would take place when the average CPU utilization exceeds 50% of the available CPU resources.
It should be noted that we have seen situations where we have experienced OOM's, but no scaling events have taken place as the CPU utilization never exceeded 50% - going forward we should look to modify this metric to mitigate these events if at all possible.
Pod Disruption Budget
There is a Pod Disruption Budget (PDB) present in the staging environment scoped to UAT only - uat-pdb.yaml
This isn't required in Alpha or CI do not have the requirement to be as highly available as UAT does.
Metadata
metadata:
name: graphql-staging-pdb
namespace: graphql-staging
In this section we see the PDB being associated with the graphql-staging namespace, and given a unique name.
Spec
MaxUnavailable
maxUnavailable: 1
This details the maximum number of pods that can be unavailable within a specified deployment - in this case graphql-uat. Here that maximum is 1.
Selector
selector:
matchLabels:
name: graphql-uat
This section stipulates which deployment this PDB is associated to, in this case graphql-uat.
Secrets
This directory holds the base64 encoded secrets held, and used, in this environment.
There are 2 secrets held in this directory:-
apollo-key.ymlcert.yml
Apollo Key
The apollo key secret holds the license key for apollo engine, which is what serves GraphQL.
Cert
This secret holds the SSL certificate and key that is used to secure traffic to the pods - this is the secret used in the Ingress.
production
There is a great deal of similarity between staging and production. The former has more deployments within it, however if we compare production with only the UAT specific config in staging we will see they are nearly identical. The differences are detailed below:-
n.b. namespace and metadata differences will not be mentioned here.
Deployment
The production deployment differs from the UAT deployment in the number of replicas. Production requires 3, whilst UAT only requires 1.
As well as this, the contianer used by production is the one created from master (tagged accordingly) whereas UAT tracks develop.
Service
There are no differences between the UAT and production service.
Ingress
Aside from there being fewer hosts and rules in the production ingress there is no functional difference between production and staging.
Namespace
There are no differences between the UAT and production namespace definition.
Horizontal Pod Autoscaler
The UAT and production HPA's differ only on the maxReplica field with production requiring 3 to UAT's 1. This tracks directly with the difference found between the UAT and production deployment.
Pod Disruption Budget
There are no differences between the UAT and production PDB.
Secrets
The values stored in the secrets in production differ from those in UAT/staging, however the name of the secrets and configuration is the same for both.
CI/CD
The CI/CD implementation for the current GraphQL is interesting to say the least. Although CI/CD is possible for Terraform and Kubernetes this was not and has not been implemented. As such the only part of this that has automated build and deployment is the creation and storage of the GraphQL containers. Although we have CI templates for building Docker containers, this is currently not used.
We previously made use of Cloud Build and Google Cloud Repositories/Registries however we moved to a Gitlab approach to reduce technical sprawl approximately a year ago.
Gitlab Configuration
The CI configuration for this project is made up of four (4) parts:-
- Build
There are two steps to the build phase of this CI file.
The first is building the app, which is only ever done on a branch to ensure that the changes made on the branch have not introduced any issues to the code base.
The scond is the building of the container itself, which is done using the Dockerfile. The building of the container is done at two (2) different points: on push to feature branch (to ensure the container builds for new changes) and on push to master (this builds the image that is to be used in the staging and production clsuters).
When a container is built for the cluster's (on push to master), the resulting container is pushed into Gitlab's container registry so that it can be subsequently tagged and pushed up to GCP. This does not happen for containers that are built for feature branches.
- Tagging master
This step takes the latest container created from master branch, which was previously built and tagged with the SHA of the commit, and retags it as latest and pushes it to the Gitlab container registry.
- Pushing to GCP
With this step we take the container with the latest tag, which was created form master rbanc, and push that into the two (2) GCP Container resgistries so that it can be used in the kubernetes cluster - the Gitlab hosted ones are not accessible to the Kube cluster.
Note this is pushed to a registry in both the production and staging GCP accounts. In an ideal world this would be a centralised registry to reduce duplication. The two registries are:-
- Staging -
eu.gcr.io/careful-alloy-189615/gitlab-graphql - Production -
eu.gcr.io/raphaproduction-221010/gitlab-graphql
- Set Images
This step is what actually deploys the changes to the clusters.
This job in essence uses a kubectl command to set the image for the relevant deployment in the cluster to be that of the latest container.
It should be noted that we need to use the commit SHA instead of the tag latest here as Kube is unable to differentiate between two containers with the same tag (i.e. where two different containers are both tagged as latest).