Product Indexing
Proposal
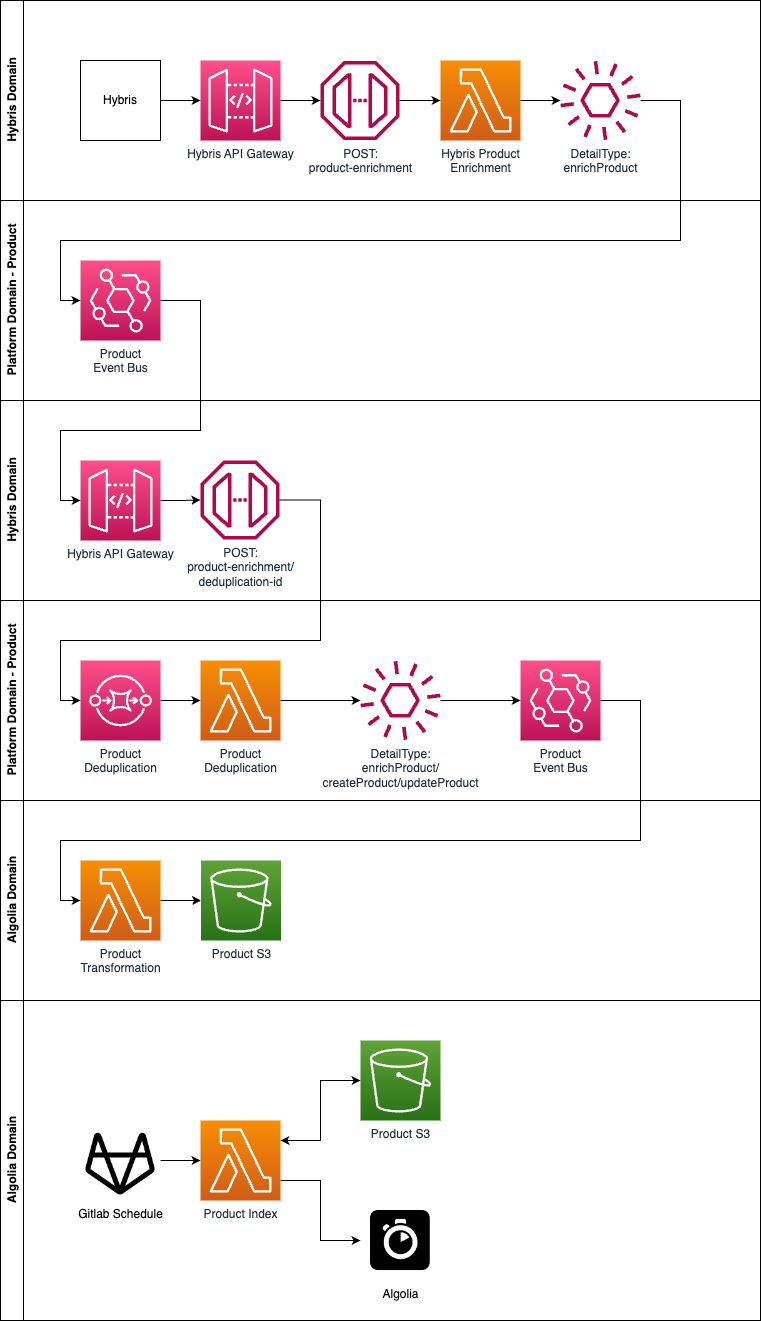
Below shows our proposal for the product service. All middleware from Hybris to the Product Event Bus after deduplication already exists. The JSON object in the Product Event Bus follows the following schema. This whole process happens when the following attributes are updated or created in Hybris.
- Name
- Description
- Summary
- Approval status
- Super categories
- Default category
- Images in normal field
- Base product
Note: Bundles and custom products are NOT sent
Once the Product Event Bus receives a product we will then being by ingesting that event in the Algolia domain. Firstly we will do this by having a Lambda performing the transformation of the product object so it follows the Algolia Product Schema. Once this has been transformed we will send the JSON object to S3. The reasoning for this is so we can send batch updates at an interval we see fit. The secondary process here is we will use Gitlab Schedules to trigger a Product Indexing Lambda in the Algolia domain. This will be responsible for:
- Getting product data from S3 in batch
- Checking for them in Algolia. This is so we either create them or do a partial update
- For partial updates, we need these to be immutable so we must copy nested attributes such as price or size so we do not overwrite
- Sending them to Algolia in batch to index
- Removing them from S3 so they are not re-processed
Batching
When sending data to Algolia, it’s best to send several records simultaneously instead of individually. It reduces network calls and speeds up indexing, especially when we have a lot of records, but in general we should send indexing operations in batches whenever possible.
For optimal indexing performance, we should aim for a batch size of about 10 MB, representing between 1,000 and 10,000 records, depending on the average our record size.
Examples
When creating records or updating nested objects in a record (price/size)
When using the saveObjects method, the API client automatically chunks our records into batches of 1,000 objects.
const algoliasearch = require('algoliasearch')
const fs = require('fs');
const StreamArray = require('stream-json/streamers/StreamArray');
const client = algoliasearch('CLIENT_ID', 'WRITE_API_KEY');
const index = client.initIndex('index');
const stream = fs.createReadStream('index.json').pipe(StreamArray.withParser());
let chunks = [];
stream
.on('data', ({ value }) => {
chunks.push(value);
if (chunks.length === 10000) {
stream.pause();
index
.saveObjects(chunks, { autoGenerateObjectIDIfNotExist: true })
.then(() => {
chunks = [];
stream.resume();
})
.catch(console.error);
}
})
.on('end', () => {
if (chunks.length) {
index.saveObjects(chunks, {
autoGenerateObjectIDIfNotExist: true
}).catch(console.error);
}
})
.on('error', err => console.error(err));
Partial update multiple objects in a single call
The partialUpdateObjects method lets you update one or more attributes of an existing object. Please note that this only works for first-level attributes. Specifying a nested attribute treats it as a replacement of its first-level ancestor. To change nested attributes, we need to use the saveObjects method. We can retrieve the object’s data by using the getObjects method.
This method lets you update only a part of an existing object by adding new attributes or updating existing ones. It requires an objectID:
- If the objectID exists, Algolia replaces the attributes
- If the objectID is specified but doesn’t exist, Algolia creates a new record
- If the objectID isn’t specified, the method returns an error
Note: When updating many objects, there is a rate limit.
const objects = [{
firstname: 'Jimmie',
objectID: 'myID1'
}, {
firstname: 'Warren',
objectID: 'myID2'
}];
index.partialUpdateObjects(objects).then(({ objectIDs }) => {
console.log(objectIDs);
});